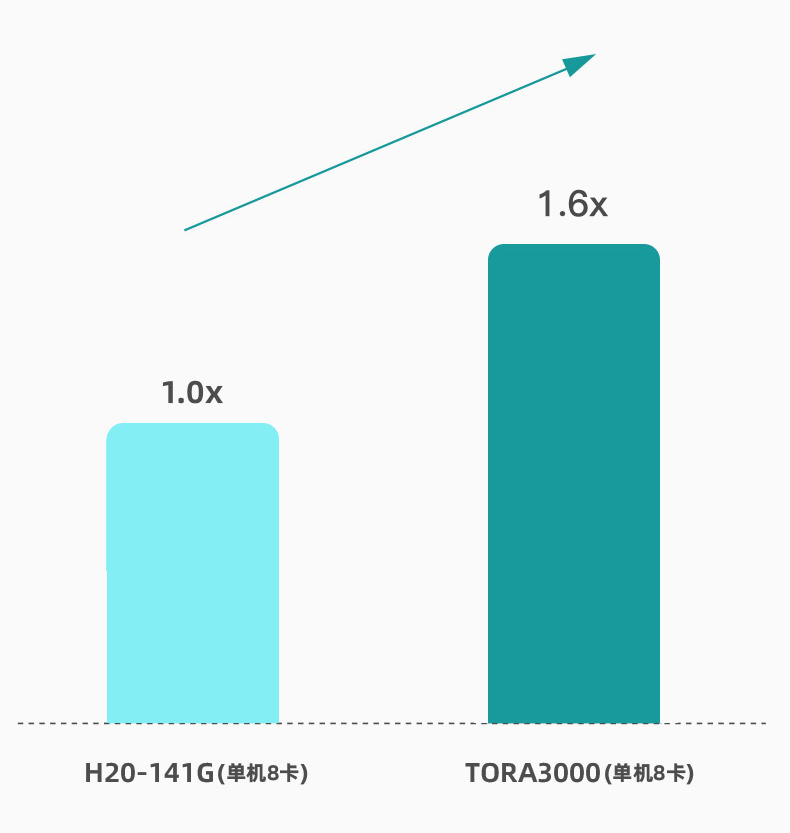
| 测试环境 | ||||
| 测试机型 | 毅伯智算TORA TEK 3000(单机8卡) | 英伟达H20-141G(单机8卡) | ||
| GPU型号 | AMD instinct OAM GPU | Nvidia H20 | ||
| GPU型号 | 1536G(单卡192G*8) | 1128G(单卡141G*8) | ||
| 测试模型 | DeepSeek-R1-671B(满血版) | |||
| 推理框架 | TORA-TEK-vLLM 2.0 | SGLang | ||
| 全栈式AI训推平台 | 包含毅伯智算自研中间件、算子库、各种用于 训推的框架等完备工具链,全面兼容CUDA生态 |
CUDA | ||
| 模型精度 | DeepSeek原生FP8格式,未进行任何量化处理,保证性能最优 | |||
| 开源数据集 | ShareGPT Vicuna unfiltered | |||
| 开源测试工具 | vllm benchmark_serving.py | Sglang.bench serving | ||

| 满血一体机方案 | 精 度 | 服务器数量(台) | 方案总显存(GB) |
| 英伟达H20-96G | FP8 | 2 | 1536 |
| 英伟达H20-141G | FP8 | 1 | 1128 |
| 华为910B-64G | INT8 | 2 | 1024 |
| 华为910B-64G | FP16 | 4 | 2048 |
| 毅伯智算TORA TEK 3000 | FP8 | 1 | 1536 |